Buenas, retomo después de una pausa forzada por varios cambios (nueva casa, trabajo y niños que arrancan liceo), con varios tips técnicos para compartir en breve, y para recordarles los eventos que se vienen en la región en breve.
El Oracle Technology Network Tour Latin América (más conocido como OTN Tour) arranca el 2 de agosto en San Pablo, visita 12 países, y llega a Montevideo el 14 y 15 de Agosto. Todos los detalles de estos eventos en el sitio de Oracle.
Estos eventos son realizados gracias al esfuerzo de los grupos de usuarios de Latinoamérica, con apoyo de OTN y sponsors locales para solventar los gastos, y no sería posible sin el trabajo honorario de mucha gente que dedicas muchas horas de su tiempo personal a que esto sea posible.
Así que si trabajan con Oracle o les interesa aprender, tómense un día libre y acérquense. Van a aprender en un solo día muchísimo, y a diferencia del muy buen evento virtual que organizó OTN hace un par de semanas, van a poder interactuar en persona con reconocidos expertos, conocerlos de cerca, además conocer a otros profesionales con inquietudes similares, y quedar en contacto con grandes personas.
Como no puedo evitarlo, tengo que pedirles que si andan por Montevideo se arrimen a nuestro evento, y si tienen ganas de hablar de Bases de datos después, invito la cerveza.
Un saludo.
viernes, 18 de julio de 2014
domingo, 30 de marzo de 2014
Consultas para ver atributos de tablas e índices particionados
Este post es para compartir un par de consultas que uso muy seguido y quiero dejar a mano en el blog, ya que no tengo un área de scripts.
Si usamos habitualmente la línea de comando para administrar una base de datos, tenemos a mano muchos scripts SQL para distintas tareas. Para consultas simples no es tan necesario, como por ejemplo ver los índices de una tabla. Pero cuando trabajamos con tablas particionadas, lleva un poco más volver a escribir esa consulta que nos muestra todos los datos que nos interesa. Tener a mano el script SQL es útil para ahorrarnos escribirlo de nuevo cada vez.
Actualmente hay muchas herramientas gráficas/web de administración que nos hace dejar de lado usar este tipo de scripts para consultar metadata de la base de datos. Usar scripts también puede ser un hábito adquirido con el tiempo (señal del paso del tiempo :)), aunque hay casos en que es necesario. Uno de ellos es cuando hay firewalls o medidas de seguridad que solo permiten acceso a la base de datos mediante una terminal. Aunque los firewalls se puedan esquivar usando túneles con ssh para utilitarios cliente/servidor (como SQL Developer o MySQL Workbench), para utilitarios que publican un acceso web es más complicado (Grid Control), y ahí vuelven a tener sentido los scripts.
Así que hecha la introducción, estos son un par de scripts útiles para ver información de una tabla particionada y sus índices. Cuando no hay particiones, estos datos se pueden sacar con una consulta simple sobre DBA_TABLES y DBA_IND_COLUMNS sin mucha complicación.
Para ilustrarlo mejor, un ejemplo usando estas tablas:
Así vemos por separado sus particiones:
Juntamos ambas consultas en una sola:
La misma idea aplicada a los índices nos lleva a esta consulta, para ver los índices, saber si están particionados y algún dato más:
Espero les sea útil
Si usamos habitualmente la línea de comando para administrar una base de datos, tenemos a mano muchos scripts SQL para distintas tareas. Para consultas simples no es tan necesario, como por ejemplo ver los índices de una tabla. Pero cuando trabajamos con tablas particionadas, lleva un poco más volver a escribir esa consulta que nos muestra todos los datos que nos interesa. Tener a mano el script SQL es útil para ahorrarnos escribirlo de nuevo cada vez.
Actualmente hay muchas herramientas gráficas/web de administración que nos hace dejar de lado usar este tipo de scripts para consultar metadata de la base de datos. Usar scripts también puede ser un hábito adquirido con el tiempo (señal del paso del tiempo :)), aunque hay casos en que es necesario. Uno de ellos es cuando hay firewalls o medidas de seguridad que solo permiten acceso a la base de datos mediante una terminal. Aunque los firewalls se puedan esquivar usando túneles con ssh para utilitarios cliente/servidor (como SQL Developer o MySQL Workbench), para utilitarios que publican un acceso web es más complicado (Grid Control), y ahí vuelven a tener sentido los scripts.
Así que hecha la introducción, estos son un par de scripts útiles para ver información de una tabla particionada y sus índices. Cuando no hay particiones, estos datos se pueden sacar con una consulta simple sobre DBA_TABLES y DBA_IND_COLUMNS sin mucha complicación.
Para ilustrarlo mejor, un ejemplo usando estas tablas:
select table_name, num_rows from dba_tables where table_name like 'BIGTBL%'; TABLE_NAME NUM_ROWS ------------------------------ ---------- BIGTBL_PART_FACT 34718511 BIGTBL_PART_ID 41529989 BIGTBL 5931843 3 rows selected.
Así vemos por separado sus particiones:
break on t.table_NAME on t.partitioning_type on t.partition_count on t.status select t.table_NAME, t.partitioning_type tipo, t.partition_count particiones, t.status, c.COLUMN_NAME, c.COLUMN_POSITION from DBA_PART_KEY_COLUMNS c, dbA_part_tables t where t.table_name = c.name and c.owner = t.owner and t.table_name like 'BIGTBL%' order by c.name, c.COLUMN_POSITION; TABLE_NAME TIPO PARTICIONES STATUS COLUMN_NAME COLUMN_POSITION ------------------------------ --------- ----------- -------- -------------------- --------------- BIGTBL_PART_FACT RANGE 50 VALID NRO_FACT 1 BIGTBL_PART_ID RANGE 50 VALID ID 1 2 rows selected.
Juntamos ambas consultas en una sola:
col part_col for a30 select t.table_NAME, t.num_rows, p.partitioning_type particion, p.partition_count "#part", p.status, c.COLUMN_NAME part_col, c.COLUMN_POSITION pos from dbA_tables t, DBA_PART_KEY_COLUMNS c, dbA_part_tables p where t.table_name = p.table_name(+) and t.owner=p.owner(+) and t.table_name = c.name(+) and t.owner = c.owner(+) and t.table_name like 'BIGTBL%' order by t.table_name, c.COLUMN_POSITION; TABLE_NAME NUM_ROWS PARTICION #part STATUS PART_COL POS ------------------------------ ---------- --------- ---------- -------- ------------------------------ ---------- BIGTBL_PART_FACT 34718511 RANGE 50 VALID NRO_FACT 1 BIGTBL_PART_ID 41529989 RANGE 50 VALID ID 1 BIGTBL 5931843 3 rows selected.
La misma idea aplicada a los índices nos lleva a esta consulta, para ver los índices, saber si están particionados y algún dato más:
col index_name for a30 select c.index_name, uniqueness, i.partitioned, p.partitioning_type tipo, locality, c.column_name, column_position pos from dba_ind_columns c, dba_indexes i, dba_part_indexes p where i.index_name=c.index_name and c.index_owner=i.owner and c.table_name=i.table_name and c.table_owner=i.table_owner and i.owner=p.owner(+) and i.index_name=p.index_name(+) and i.table_name=p.table_name(+) and c.table_name='BIGTBL_PART_ID' order by c.index_name, c.column_position; INDEX_NAME UNIQUENES PAR TIPO LOCALI COLUMN_NAME POS ------------------------------ --------- --- --------- ------ -------------------- ---------- IDX_BIGTBL_PART_2 NONUNIQUE NO COD_DOC 1 IDX_BIGTBL_PART_2 NONUNIQUE NO COD_LOCAL 2 IDX_BIGTBL_PART_ID UNIQUE YES RANGE LOCAL NRO_FACT 1 3 rows selected.
Espero les sea útil
sábado, 29 de marzo de 2014
Preguntas y respuestas de la presentación sobre RAC
Muchas gracias a todos los que me acompañaron en la presentación sobre Oracle RAC hace unos días.
Hubo varias preguntas al final, y algunos asistentes me pidieron que les enviara referencias. No tuve tiempo de tomar nota de quién hizo esas preguntas antes de que se cerrara la sesión, así que dejo acá las respuestas, que además sirven para ampliar el material usado en la presentación.
Transcribo las preguntas de memoria, así que espero que sean lo más parecido posible a la realidad. Y aprovecho a desarrollarlas un poco más.
En Enterprise Edition se permiten alternativas (documentadas en la matriz de certificación en el sitio de soporte), aunque Oracle ASM es la recomendada para la base de datos y los archivos OCR y voting disk usados por clusterware. Este es justamente uno de los puntos fuertes a favor de usar RAC, contar con soporte de todos los componentes de la infraestructura por parte del mismo proveedor, lo que da cierta garantía sobre la integración de las partes y se minimiza el tiempo de resolución de incidentes.
Hubo varias preguntas al final, y algunos asistentes me pidieron que les enviara referencias. No tuve tiempo de tomar nota de quién hizo esas preguntas antes de que se cerrara la sesión, así que dejo acá las respuestas, que además sirven para ampliar el material usado en la presentación.
Transcribo las preguntas de memoria, así que espero que sean lo más parecido posible a la realidad. Y aprovecho a desarrollarlas un poco más.
- ¿Se necesita Oracle ASM con Oracle RAC 11g?
En Enterprise Edition se permiten alternativas (documentadas en la matriz de certificación en el sitio de soporte), aunque Oracle ASM es la recomendada para la base de datos y los archivos OCR y voting disk usados por clusterware. Este es justamente uno de los puntos fuertes a favor de usar RAC, contar con soporte de todos los componentes de la infraestructura por parte del mismo proveedor, lo que da cierta garantía sobre la integración de las partes y se minimiza el tiempo de resolución de incidentes.
Un buen ejemplo de que siempre es necesario consultar la documentación es que HP Serviceguard Storage Management Suite no aparece soportado en 12.1 y sí lo estaba en 11.2 (junto a otros productos).
Si el upgrade incluye usar nuevo hardware, se puede realizar la instalación con tranquilidad sobre el hardware nuevo para luego evaluar estrategias para replicar datos sin afectar el sistema de producción. Más adelante se aclaró que el upgrade sería sobre el mismo hardware, lo que plantea desafíos adicionales:
- se debe validar que la versión del Sistema operativo (SO) permita realizar un upgrade a la nueva versión (hay años de diferencia entre las versiones, y si bien se certifican nuevas versiones de la base de datos con versiones viejas del SO, normalmente requiere parches en el SO que pueden no estar instalados). Si se requieren parches, se agrega complejidad al proceso y posiblemente una ventana adicional de indisponibilidad.
- al trabajar sobre los mismos servidores que soportan un sistema en producción, se debe buscar un procedimiento que minimice el impacto en la disponiblidad del sistema. Por ejemplo, dependiendo de la cantidad de servidores que tenga el cluster, se podría ir quitando de a un servidor y hacer la actualización mientras el resto sigue funcionando (método conocido como rolling upgrade). Un punto importante es que ASM permite rolling upgrades a partir de 11g, por lo que se debe planificar un tiempo de indisponiblidad para realizar esta actualización desde 10g cuando se llegue al último servidor.
Por culminar, algo obvio pero que no está de mas recordarlo: este tipo de trabajo requiere mucha validación previa, por lo que es imprescindible contar con un ambiente de prueba donde realizar el procedimiento de upgrade completo, y se puedan realizar ajustes y automatizar todo lo posible previo a su ejecución en producción.
La respuesta obvia podría ser habilitar la funcionalidad de monitoreo de índices, disponible desde 9i.
Aunque esta solución es muy simple, no es la mejor porque puede detectar casos que no nos interesan, ya que no registra la frecuencia con que fueron usados. Por ejemplo, un proceso agendado que ejecute por la noche y no tenga impacto en el uso del sistema puede ser el único que use un índice.
Otro aspecto importante para buscar oportunidades de reducir la generación de redo es eliminar índices redundantes, cosa que no tiene mucho que ver con esta detección índices usados.
En los foros de OTN hay varias preguntas similares, y esta es un buen ejemplo con varias respuestas que incluyen todos estos detalles.
Otro enfoque para identificar el uso de índices junto a la frecuencia con que son usados es aprovechar los datos capturados por AWR, si tenemos la versión Oracle Enterprise Edition y la licencia del Diagnostic Pack. Esto es algo bastante comentado en la comunidad, y por ejemplo en este muy completo post se pueden ver scripts y ejemplos de como obtener esta información.
- ¿Recomendaciones para hacer upgrade de RAC 10g a RAC 11g?
Si el upgrade incluye usar nuevo hardware, se puede realizar la instalación con tranquilidad sobre el hardware nuevo para luego evaluar estrategias para replicar datos sin afectar el sistema de producción. Más adelante se aclaró que el upgrade sería sobre el mismo hardware, lo que plantea desafíos adicionales:
- se debe validar que la versión del Sistema operativo (SO) permita realizar un upgrade a la nueva versión (hay años de diferencia entre las versiones, y si bien se certifican nuevas versiones de la base de datos con versiones viejas del SO, normalmente requiere parches en el SO que pueden no estar instalados). Si se requieren parches, se agrega complejidad al proceso y posiblemente una ventana adicional de indisponibilidad.
- al trabajar sobre los mismos servidores que soportan un sistema en producción, se debe buscar un procedimiento que minimice el impacto en la disponiblidad del sistema. Por ejemplo, dependiendo de la cantidad de servidores que tenga el cluster, se podría ir quitando de a un servidor y hacer la actualización mientras el resto sigue funcionando (método conocido como rolling upgrade). Un punto importante es que ASM permite rolling upgrades a partir de 11g, por lo que se debe planificar un tiempo de indisponiblidad para realizar esta actualización desde 10g cuando se llegue al último servidor.
Por culminar, algo obvio pero que no está de mas recordarlo: este tipo de trabajo requiere mucha validación previa, por lo que es imprescindible contar con un ambiente de prueba donde realizar el procedimiento de upgrade completo, y se puedan realizar ajustes y automatizar todo lo posible previo a su ejecución en producción.
- ¿Cómo identificar índices que no se usan?
La respuesta obvia podría ser habilitar la funcionalidad de monitoreo de índices, disponible desde 9i.
Aunque esta solución es muy simple, no es la mejor porque puede detectar casos que no nos interesan, ya que no registra la frecuencia con que fueron usados. Por ejemplo, un proceso agendado que ejecute por la noche y no tenga impacto en el uso del sistema puede ser el único que use un índice.
Otro aspecto importante para buscar oportunidades de reducir la generación de redo es eliminar índices redundantes, cosa que no tiene mucho que ver con esta detección índices usados.
En los foros de OTN hay varias preguntas similares, y esta es un buen ejemplo con varias respuestas que incluyen todos estos detalles.
Otro enfoque para identificar el uso de índices junto a la frecuencia con que son usados es aprovechar los datos capturados por AWR, si tenemos la versión Oracle Enterprise Edition y la licencia del Diagnostic Pack. Esto es algo bastante comentado en la comunidad, y por ejemplo en este muy completo post se pueden ver scripts y ejemplos de como obtener esta información.
- ¿ASM puede saturar los discos?
ASM es el intermediario para gestionar los discos, pero el acceso a los bloques en disco lo hace el proceso de usuario que lo necesita (y los procesos de la base para escribir). Entonces no hay overhead en el acceso a disco asociado al uso de ASM.
El rendimiento de los discos va a ser el mismo que se pueda obtener por fuera de ASM, con acceso directo desde el sistema operativo (SO). Una buena nota de soporte que intenta aclarar esto es "Comparing ASM to Filesystem in benchmarks (Doc ID 1153664.1)".
Cualquier problema en la configuración que los hace visibles al SO y que pueda impactar en su rendimiento se va a extender a cualquier programa que los use. Esto incluye la conectividad al storage y la redundancia (multipath). Un ejemplo análogo es el uso de raid, donde es posible ver configuraciones que no logran la mejor performance, y cualquier filesystem que utilice estos discos va a sufrir su impacto.
Otra interpretación de la pregunta puede ser apuntando a las tareas internas que ejecuta ASM para garantizar la redundancia configurada. Hay operaciones internas de rebalanceo cuando cambia la cantidad de discos disponibles en los disk groups. Cuando ésta ejecuta se agrega actividad sobre la que ya existe en los discos, y se puede controlar su impacto en la performance con el parámetro ASM_POWER_LIMIT. El avance de estas operaciones se puede seguir en la vista GV$ASM_OPERATION.
Espero que les sea útil.
Un saludo.
El rendimiento de los discos va a ser el mismo que se pueda obtener por fuera de ASM, con acceso directo desde el sistema operativo (SO). Una buena nota de soporte que intenta aclarar esto es "Comparing ASM to Filesystem in benchmarks (Doc ID 1153664.1)".
Cualquier problema en la configuración que los hace visibles al SO y que pueda impactar en su rendimiento se va a extender a cualquier programa que los use. Esto incluye la conectividad al storage y la redundancia (multipath). Un ejemplo análogo es el uso de raid, donde es posible ver configuraciones que no logran la mejor performance, y cualquier filesystem que utilice estos discos va a sufrir su impacto.
Otra interpretación de la pregunta puede ser apuntando a las tareas internas que ejecuta ASM para garantizar la redundancia configurada. Hay operaciones internas de rebalanceo cuando cambia la cantidad de discos disponibles en los disk groups. Cuando ésta ejecuta se agrega actividad sobre la que ya existe en los discos, y se puede controlar su impacto en la performance con el parámetro ASM_POWER_LIMIT. El avance de estas operaciones se puede seguir en la vista GV$ASM_OPERATION.
Espero que les sea útil.
Un saludo.
lunes, 10 de marzo de 2014
Presentación sobre Oracle RAC este miércoles
El grupo de interés sobre Oracle Real Application Clusters (RACSIG) desde hace años comparte valiosa información técnica en su sitio web, y organiza presentaciones que se pueden seguir en vivo por internet (webinar o webcast). Es una organización similar a un grupo de usuarios, pero no limitado a un país, sino de alcance global.
Fui invitado a dar una presentación en español, para inaugurar el contenido de habla hispana, y será este miércoles 12 de marzo a las 13:00 hs de Uruguay (GMT-3). Los detalles aquí.
Para seguir la presentación en vivo, se deben registrar previamente en el sitio, que los llevará a este link.
Esta es una versión actualizada con funcionalidades de las últimas versiones (11g/12c) a la presentación que dí durante el OTN Tour 2011 en Montevideo, Oracle RAC sin sorpresas, donde se repasa lo que implica usar Oracle RAC, los desafíos y recomendaciones de cómo sacarle mejor provecho.
Este enfoque introductorio intenta facilitar el camino a los técnicos que están evaluando o comenzado a utilizar Oracle RAC, tarea que tiene una larga curva de aprendizaje.
Los espero.
Un saludo.
miércoles, 26 de febrero de 2014
Analizando sentencias con SQL Profile activo en Oracle
Si queremos analizar la performance de una sentencia SQL que tiene un SQL profile habilitado (Oracle 10g o posterior) sin afectar al resto de los usuarios del sistema, ¿cómo hacemos para ver el plan de ejecución original de la sentencia si no se usara el SQL profile?.
Asumiendo que lo vamos a hacer un tiempo después de tener el SQL profile activo y por lo tanto no está presente en la SGA (V$SQL) ni en el repositorio de AWR.
A continuación vemos un ejemplo completo de este comportamiento, incluyendo la creación de un SQL profile sobre una sentencia para forzar el uso de un índice, y luego cambiar este parámetro para ver el plan original, usando Oracle Enterprise Edition 11.2.0.2.
Uso el script coe_xfr_sql_profile.sql provisto por Oracle en el utilitario SQLT (ver nota de soporte 215187.1) para crear un SQL profile a partir de los hints de una sentencia previamente ejecutada. Esta es la forma más simple de crear un SQL profile para ilustrar con un ejemplo reproducible el cambio de parámetro, aunque el caso queda un tanto artificial. Hay mucha documentación sobre las formas de crear SQL Profiles, pero no es el foco de este post.
De todas formas, este procedimiento es muy útil para troubleshooting de performance, por lo que es interesante tenerlo presente, aunque en este caso solo sea para ilustrar.
Primero creo una tabla, un índice, y ejecuto una consulta que lo usa:
Ahora creamos otra consulta que hace un full scan sobre la tabla, y es a la que luego vamos a asignarle un SQL profile para que use el índice:
Ahora usamos el script coe_xfr_sql_profile.sql para crear un SQL profile a la consulta lenta (btpjqgv0u0stb) y que use el plan de la otra (2830885032). Estos son los parámetros que se le deben ingresar al script:
Lo ejecutamos:
Recién ahora estamos en la situación que me interesaba mostrar: ¿cómo hacemos para ver el plan de ejecución original de esta sentencia?. Uso el string OTRA, pero podría ser cualquier string distinto de DEFAULT:
Espero les sea útil.
Asumiendo que lo vamos a hacer un tiempo después de tener el SQL profile activo y por lo tanto no está presente en la SGA (V$SQL) ni en el repositorio de AWR.
No es necesario deshabilitar ni borrar el SQL profile existente, se puede cambiar el parámetro SQLTUNE_CATEGORY a nivel de sesión para que no se use el SQL profile activo:
Los SQL profile se crean en una categoría (por defecto 'default'), y se usan si la categoría de la sesión (este parámetro) coincide con la del SQL profile creado. Para ver el plan de ejecución original de la sentencia sin usar el SQL profile activo, alcanza con asignar un string cualquiera a la categoría de la sesión actual.SQL> alter session set sqltune_category='OTRA';
A continuación vemos un ejemplo completo de este comportamiento, incluyendo la creación de un SQL profile sobre una sentencia para forzar el uso de un índice, y luego cambiar este parámetro para ver el plan original, usando Oracle Enterprise Edition 11.2.0.2.
Uso el script coe_xfr_sql_profile.sql provisto por Oracle en el utilitario SQLT (ver nota de soporte 215187.1) para crear un SQL profile a partir de los hints de una sentencia previamente ejecutada. Esta es la forma más simple de crear un SQL profile para ilustrar con un ejemplo reproducible el cambio de parámetro, aunque el caso queda un tanto artificial. Hay mucha documentación sobre las formas de crear SQL Profiles, pero no es el foco de este post.
De todas formas, este procedimiento es muy útil para troubleshooting de performance, por lo que es interesante tenerlo presente, aunque en este caso solo sea para ilustrar.
Primero creo una tabla, un índice, y ejecuto una consulta que lo usa:
Ya tenemos nuestra tabla PP con un índice sobre la columna N, y la consulta que lo usa.oracle@oraculo:~> sqlplus / as sysdba SQL*Plus: Release 11.2.0.2.0 Production on Mié Feb 26 14:55:15 2014 Copyright (c) 1982, 2010, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production With the Partitioning, Real Application Clusters and Automatic Storage Management options 14:56:08 SQL> alter session set current_schema=PRU; Session altered. 14:56:46 SQL> create table pp(n number, c varchar2(100)); Table created. 14:57:03 SQL> insert into pp select rownum, object_id from dba_objects where rownum < 100; 99 rows created. 14:57:33 SQL> create index pp_idx on pp(n); Index created. 14:57:52 SQL> select * from pp where n=1; N C ---------- --------------------------------------------------------------------------------- 1 28 14:59:17 SQL> select * from table(dbms_xplan.display_cursor); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------------- SQL_ID 86svufrd72xqg, child number 0 ------------------------------------- select * from pp where n=1 Plan hash value: 2830885032 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 1 (100)| | | 1 | TABLE ACCESS BY INDEX ROWID| PP | 1 | 65 | 1 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | PP_IDX | 1 | | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("N"=1) Note ----- - dynamic sampling used for this statement (level=2) 23 rows selected.
Ahora creamos otra consulta que hace un full scan sobre la tabla, y es a la que luego vamos a asignarle un SQL profile para que use el índice:
Vemos los SQL_ID de ambas consultas, junto con el plan de ejecución usado.14:59:22 SQL> select /*+ full(pp)*/ * from pp where n=1; N C ---------- ----------------------------------------------------------------------------------- 1 28 14:59:37 SQL> select * from table(dbms_xplan.display_cursor); PLAN_TABLE_OUTPUT ---------------------------------------------------------------------------------------------- SQL_ID btpjqgv0u0stb, child number 0 ------------------------------------- select /*+ full(pp)*/ * from pp where n=1 Plan hash value: 2338859486 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 3 (100)| | |* 1 | TABLE ACCESS FULL| PP | 1 | 65 | 3 (0)| 00:00:01 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("N"=1) Note ----- - dynamic sampling used for this statement (level=2) 22 rows selected. 15:02:10 SQL> col sql_text for a45 15:02:10 SQL> select sql_id, plan_hash_value, executions, sql_text from v$sql where sql_id in ('btpjqgv0u0stb','86svufrd72xqg'); SQL_ID PLAN_HASH_VALUE EXECUTIONS SQL_TEXT ------------- --------------- ---------- --------------------------------------------- btpjqgv0u0stb 2338859486 1 select /*+ full(pp)*/ * from pp where n=1 86svufrd72xqg 2830885032 1 select * from pp where n=1
Ahora usamos el script coe_xfr_sql_profile.sql para crear un SQL profile a la consulta lenta (btpjqgv0u0stb) y que use el plan de la otra (2830885032). Estos son los parámetros que se le deben ingresar al script:
Vemos que se ejecutó de forma exitosa, así que nos generó un script que crea el SQL profile.SQL> sta coe_xfr_sql_profile.sql Parameter 1: SQL_ID (required) Enter value for 1: btpjqgv0u0stb PLAN_HASH_VALUE AVG_ET_SECS --------------- ----------- 2338859486 ,004 Parameter 2: PLAN_HASH_VALUE (required) Enter value for 2: 2830885032 Values passed to coe_xfr_sql_profile: ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ SQL_ID : "btpjqgv0u0stb" PLAN_HASH_VALUE: "2830885032" SQL>BEGIN 2 IF :sql_text IS NULL THEN 3 RAISE_APPLICATION_ERROR(-20100, 'SQL_TEXT for SQL_ID &&sql_id. was not found in memory (gv$sqltext_with_newlines) or AWR (dba_hist_sqltext).'); 4 END IF; 5 END; 6 / SQL>SET TERM OFF; SQL>BEGIN 2 IF :other_xml IS NULL THEN 3 RAISE_APPLICATION_ERROR(-20101, 'PLAN for SQL_ID &&sql_id. and PHV &&plan_hash_value. was not found in memory (gv$sql_plan) or AWR (dba_hist_sql_plan).'); 4 END IF; 5 END; 6 / SQL>SET TERM OFF; Execute coe_xfr_sql_profile_btpjqgv0u0stb_2830885032.sql on TARGET system in order to create a custom SQL Profile with plan 2830885032 linked to adjusted sql_text. COE_XFR_SQL_PROFILE completed.
Lo ejecutamos:
El SQL profile se creó, así que validamos si la consulta que antes hacía un acceso full sobre la tabla ahora toma el índice:SQL> sta coe_xfr_sql_profile_btpjqgv0u0stb_2830885032.sql SQL> REM SQL> REM $Header: 215187.1 coe_xfr_sql_profile_btpjqgv0u0stb_2830885032.sql 11.4.4.4 2014/02/26 carlos.sierra $ SQL> REM SQL> REM Copyright (c) 2000-2012, Oracle Corporation. All rights reserved. SQL> REM SQL> REM AUTHOR SQL> REM carlos.sierra@oracle.com SQL> REM SQL> REM SCRIPT SQL> REM coe_xfr_sql_profile_btpjqgv0u0stb_2830885032.sql SQL> REM SQL> REM DESCRIPTION SQL> REM This script is generated by coe_xfr_sql_profile.sql SQL> REM It contains the SQL*Plus commands to create a custom SQL> REM SQL Profile for SQL_ID btpjqgv0u0stb based on plan hash SQL> REM value 2830885032. SQL> REM The custom SQL Profile to be created by this script SQL> REM will affect plans for SQL commands with signature SQL> REM matching the one for SQL Text below. SQL> REM Review SQL Text and adjust accordingly. SQL> REM SQL> REM PARAMETERS SQL> REM None. SQL> REM SQL> REM EXAMPLE SQL> REM SQL> START coe_xfr_sql_profile_btpjqgv0u0stb_2830885032.sql; SQL> REM SQL> REM NOTES SQL> REM 1. Should be run as SYSTEM or SYSDBA. SQL> REM 2. User must have CREATE ANY SQL PROFILE privilege. SQL> REM 3. SOURCE and TARGET systems can be the same or similar. SQL> REM 4. To drop this custom SQL Profile after it has been created: SQL> REM EXEC DBMS_SQLTUNE.DROP_SQL_PROFILE('coe_btpjqgv0u0stb_2830885032'); SQL> REM 5. Be aware that using DBMS_SQLTUNE requires a license SQL> REM for the Oracle Tuning Pack. SQL> REM 6. If you modified a SQL putting Hints in order to produce a desired SQL> REM Plan, you can remove the artifical Hints from SQL Text pieces below. SQL> REM By doing so you can create a custom SQL Profile for the original SQL> REM SQL but with the Plan captured from the modified SQL (with Hints). SQL> REM SQL> WHENEVER SQLERROR EXIT SQL.SQLCODE; SQL> REM SQL> VAR signature NUMBER; SQL> VAR signaturef NUMBER; SQL> REM SQL> DECLARE 2 sql_txt CLOB; 3 h SYS.SQLPROF_ATTR; 4 PROCEDURE wa (p_line IN VARCHAR2) IS 5 BEGIN 6 DBMS_LOB.WRITEAPPEND(sql_txt, LENGTH(p_line), p_line); 7 END wa; 8 BEGIN 9 DBMS_LOB.CREATETEMPORARY(sql_txt, TRUE); 10 DBMS_LOB.OPEN(sql_txt, DBMS_LOB.LOB_READWRITE); 11 -- SQL Text pieces below do not have to be of same length. 12 -- So if you edit SQL Text (i.e. removing temporary Hints), 13 -- there is no need to edit or re-align unmodified pieces. 14 wa(q'[select /*+ full(pp)*/ * from pp where n=1]'); 15 DBMS_LOB.CLOSE(sql_txt); 16 h := SYS.SQLPROF_ATTR( 17 q'[BEGIN_OUTLINE_DATA]', 18 q'[IGNORE_OPTIM_EMBEDDED_HINTS]', 19 q'[OPTIMIZER_FEATURES_ENABLE('11.2.0.2')]', 20 q'[DB_VERSION('11.2.0.2')]', 21 q'[OPT_PARAM('optimizer_index_cost_adj' 1)]', 22 q'[OPT_PARAM('optimizer_index_caching' 100)]', 23 q'[ALL_ROWS]', 24 q'[OUTLINE_LEAF(@"SEL$1")]', 25 q'[INDEX_RS_ASC(@"SEL$1" "PP"@"SEL$1" ("PP"."N"))]', 26 q'[END_OUTLINE_DATA]'); 27 :signature := DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE(sql_txt); 28 :signaturef := DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE(sql_txt, TRUE); 29 DBMS_SQLTUNE.IMPORT_SQL_PROFILE ( 30 sql_text => sql_txt, 31 profile => h, 32 name => 'coe_btpjqgv0u0stb_2830885032', 33 description => 'coe btpjqgv0u0stb 2830885032 '||:signature||' '||:signaturef||'', 34 category => 'DEFAULT', 35 validate => TRUE, 36 replace => TRUE, 37 force_match => FALSE /* TRUE:FORCE (match even when different literals in SQL). FALSE:EXACT (similar to CURSOR_SHARING) */ ); 38 DBMS_LOB.FREETEMPORARY(sql_txt); 39 END; 40 / PL/SQL procedure successfully completed. SQL> WHENEVER SQLERROR CONTINUE SQL> SET ECHO OFF; SIGNATURE --------------------- 613978514929328923 SIGNATUREF --------------------- 16370312570377067161 ... manual custom SQL Profile has been created COE_XFR_SQL_PROFILE_btpjqgv0u0stb_2830885032 completed
Perfecto, el SQL profile está haciendo lo que esperamos y está activo.15:14:08 SQL> select /*+ full(pp)*/ * from pp where n=1; N C ---------- --------------------------------------------------------------------- 1 28 15:14:09 SQL> select * from table(dbms_xplan.display_cursor); PLAN_TABLE_OUTPUT --------------------------------------------------------------------------------------------- SQL_ID btpjqgv0u0stb, child number 1 ------------------------------------- select /*+ full(pp)*/ * from pp where n=1 Plan hash value: 2830885032 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 1 (100)| | | 1 | TABLE ACCESS BY INDEX ROWID| PP | 1 | 65 | 1 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | PP_IDX | 1 | | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("N"=1) Note ----- - SQL profile coe_btpjqgv0u0stb_2830885032 used for this statement 23 rows selected. 15:14:50 SQL> select category, status 15:15:04 2 from dba_sql_profiles 15:15:09 3 where name='coe_btpjqgv0u0stb_2830885032'; CATEGORY STATUS ------------------------------ -------- DEFAULT ENABLED
Recién ahora estamos en la situación que me interesaba mostrar: ¿cómo hacemos para ver el plan de ejecución original de esta sentencia?. Uso el string OTRA, pero podría ser cualquier string distinto de DEFAULT:
Vemos que al ejecutar la sentencia se vuelve a comportar como antes, sin usar el SQL profile.15:15:50 SQL> alter session set sqltune_category='OTRA'; Session altered. 15:16:02 SQL> select /*+ full(pp)*/ * from pp where n=1; N C ---------- --------------------------------------------------------------------------------- 1 28 15:16:12 SQL> select * from table(dbms_xplan.display_cursor); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------------- SQL_ID btpjqgv0u0stb, child number 2 ------------------------------------- select /*+ full(pp)*/ * from pp where n=1 Plan hash value: 2338859486 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 3 (100)| | |* 1 | TABLE ACCESS FULL| PP | 1 | 65 | 3 (0)| 00:00:01 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("N"=1) Note ----- - dynamic sampling used for this statement (level=2) 22 rows selected.
Espero les sea útil.
lunes, 17 de febrero de 2014
Oracle RAC 12c sobre Oracle VM y VirtualBox usando Templates
OTN publicó hace unos días un hands-on lab How to Deploy a Four-Node Oracle RAC 12c Cluster in Minutes Using Oracle VM Templates, basado en una sesión del Oracle Open World 2013.
Es un artículo muy bueno, con todos los detalles para hacer la configuración e instalación, usando un equipo con 16gb de RAM para configurar 4 nodos virtuales con Oracle RAC 12c.
Pero sobre el final (y después de unas 3 hs de trabajo si se siguen las instrucciones) aclara: el objetivo del lab no es dejar corriendo el cluster porque no dan los recursos del servidor para hacerlo. Citando el texto original:
Primer intento
Segundo intento
Es un artículo muy bueno, con todos los detalles para hacer la configuración e instalación, usando un equipo con 16gb de RAM para configurar 4 nodos virtuales con Oracle RAC 12c.
Pero sobre el final (y después de unas 3 hs de trabajo si se siguen las instrucciones) aclara: el objetivo del lab no es dejar corriendo el cluster porque no dan los recursos del servidor para hacerlo. Citando el texto original:
"Note: The goal of this lab is to show how to create a four-node cluster using Oracle VM with Flex Cluster and Oracle Flex ASM, not to actually run a four-node cluster. Because of the limited resources we have on the x86 machine, the build for this four-node cluster will not finish. By comparison, a similar deployment on a bare-metal/Oracle VM environment with adequate resources would take around 30 to 40 minutes."
Ya no parece tan interesante.
Pero con mínimos cambios se puede dejar corriendo un cluster de dos nodos. Ahora es más atractivo, aunque utiliza mucho hardware, pero es una buena alternativa por varios motivos:
Pero con mínimos cambios se puede dejar corriendo un cluster de dos nodos. Ahora es más atractivo, aunque utiliza mucho hardware, pero es una buena alternativa por varios motivos:
- el tiempo que lleva de deploy es menor a otras alternativas.
- para familiarizarse con el uso de Oracle VM, templates de OVM, y Oracle RAC sin tener que instalar OVM en un servidor de pruebas.
Antes de contarles detalles sobre mi experiencia, un poco de background sobre las opciones para hacer deploys "rápidos" de máquinas virtuales con Oracle:
- Oracle RAC está soportado en producción sobre varias tecnologías de virtualización, entre ellas Oracle VM (OVM), pero no VirtualBox. OVM Server se debe instalar en el equipo que se use para virutalizar, lo que lo deja fuera notebooks o instalaciones de test que tienen otros propósitos y no hay nadie que se haga cargo de su administración (es más complejo administrar un equipo que usa OVM Server para correr virtuales que uno que usa Linux + VirtualBox)
- Oracle tiene imágenes de máquinas virtuales OVM preinstaladas con todo lo necesario (VM Templates) para distintos propósitos, entre ellos la base de datos con la opción de RAC, para 11g y 12c. No hay templates para VirtualBox.
- Hay forma de convertir las imágenes de OVM a Virtualbox, pero lleva un poco de trabajo. Si andan con tiempo, este es un muy buen artículo de cómo hacerlo, usando templates de 11.2: Build an 11gR2 RAC Cluster in VirtualBox in 1 Hour Using OVM Templates. No probé usarlo con los nuevos templates de 12.1.
- Siempre se puede crear desde cero las máquinas virtuales, instalar el sistema operativo, configurar storage, instalar Grid, Oracle y luego configurar todo. También hay guías muy buenas al respecto (como esta de Tim Hall - RAC 12c + OEL6 + virtualbox), pero es una tarea que lleva bastante más tiempo que solamente seguir la guía del lab.
Así que comparto mi experiencia usando un pc con AMD FX(tm)-8120 Eight-Core Processor de 1.4Ghz, 32Gb de RAM y openSUSE 12.3 x64
Primer intento
Siguiendo la guía al pie de la letra, el último paso que levanta las 4 VM de RAC falla con los siguientes mensajes, después de 4:45hs de haber comenzado el primer paso (sin contar el tiempo que lleva descargar los archivos que se necesitan).
tail -f /u01/racovm/buildcluster.log ERROR (node:rac2): Failed to run rootcrs.pl, status: 25 See log at: /u01/app/12.1.0/grid/cfgtoollogs/crsconfig/rootcrs_rac2_2014-02-15_11-32-40AM.log 2014-02-15 12:26:28:[girootcrslocal:Time :rac2] Completed with errors in 3230 seconds (0h:53m:50s), status: 25 INFO (node:rac0): All girootcrslocal operations completed on all (4) node(s) at: 12:27:22 2014-02-15 12:28:24:[girootcrs:Time :rac0] Completed with errors in 5497 seconds (1h:31m:37s), status: 3 2014-02-15 12:29:19:[creategrid:Time :rac0] Completed with errors in 5786 seconds (1h:36m:26s), status: 3 2014-02-15 12:29:43:[buildcluster:Time :rac0] Completed with errors in 6160 seconds (1h:42m:40s), status: 3
Segundo intento
Antes de descartar el uso de las 4 VM probé cambiar la configuración en VirtualBox del OVM server para que use 6 CPU en vez de las 2 que trae configuradas por defecto.
Usando la consola web de OVM Manager detuve las 4 VM, las borré y luego paré en VirtualBox OVM Server, cambié la configuración de CPUs, lo inicié y repetí los pasos desde el punto 11 (Clone Four Virtual Machines from the Template).
Usando la consola web de OVM Manager detuve las 4 VM, las borré y luego paré en VirtualBox OVM Server, cambié la configuración de CPUs, lo inicié y repetí los pasos desde el punto 11 (Clone Four Virtual Machines from the Template).
El resultado al levantar las VM fue el mismo: error. Aunque esta vez el servidor quedó bastante más cargado y casi no respondía
tail -f /u01/racovm/buildcluster.log ... ERROR (node:rac1): Failed to run rootcrs.pl, status: 25 See log at: /u01/app/12.1.0/grid/cfgtoollogs/crsconfig/rootcrs_rac1_2014-02-15_03-10-06PM.log 2014-02-15 16:17:24:[girootcrslocal:Time :rac1] Completed with errors in 4039 seconds (1h:07m:19s), status: 25 .... INFO (node:rac0): Waiting for all girootcrslocal operations to complete on all nodes (At 16:42:22, elapsed: 1h:28m:47s, 1 node(s) remaining, all background pid(s): 26984)...
Y esta es la carga del nodo0:
[root@rac0 ~]# uptime 18:32:08 up 4:11, 1 user, load average: 38.79, 36.94, 35.97
Intento final con dos nodos
Ahora sí para levantar un RAC con 2 nodos solamente, borré otra vez las 4 VM creadas usando la consola web de OVM Manager, y repetí los pasos desde el punto 11 (Clone Four Virtual Machines from the Template).
El comando final (./deploycluster.py) usa el archivo de parámetros de 2 nodos, y esta vez el resultado es exitoso:
[root@ovm-mgr deploycluster]# ./deploycluster.py -u admin -M rac.? -N utils/netconfig12cRAC2node.ini -P utils/params12c.ini Oracle DB/RAC OneCommand (v2.0.3) for Oracle VM - deploy cluster - (c) 2011-2013 Oracle Corporation (com: 28700:v2.0.2, lib: 180072:v2.0.3, var: 1500:v2.0.3) - v2.4.3 - ovm-mgr.oow.com (x86_64) Invoked as root at Sun Feb 16 05:35:41 2014 (size: 45500, mtime: Tue Jul 30 16:55:37 2013) Using: ./deploycluster.py -u admin -M rac.? -N utils/netconfig12cRAC2node.ini -P utils/params12c.ini INFO: Login password to Oracle VM Manager not supplied on command line or environment (DEPLOYCLUSTER_MGR_PASSWORD), prompting... Password: INFO: Attempting to connect to Oracle VM Manager... INFO: Oracle VM Client (3.2.4.524) protocol (1.9) CONNECTED (tcp) to Oracle VM Manager (3.2.4.524) protocol (1.9) IP (192.168.56.3) UUID (0004fb0000010000285d60b0071f42ae) INFO: Inspecting /SoftOracle/deploycluster/utils/netconfig12cRAC2node.ini for number of nodes defined.... INFO: Detected 2 nodes in: /SoftOracle/deploycluster/utils/netconfig12cRAC2node.ini INFO: Located a total of (2) VMs; 2 VMs with a simple name of: ['rac.0', 'rac.1'] INFO: Detected (2) Hub nodes and (0) Leaf nodes in the Flex Cluster INFO: Detected a RAC deployment... INFO: Starting all (2) VMs... INFO: VM with a simple name of "rac.0" (Hub node) is in a Stopped state, attempting to start it....OK. INFO: VM with a simple name of "rac.1" (Hub node) is in a Stopped state, attempting to start it....OK. INFO: Verifying that all (2) VMs are in Running state and pass prerequisite checks... INFO: Detected Flex ASM enabled with a dedicated network adapter (eth2), all VMs will require a minimum of (3) Vnics... .. INFO: Skipped checking memory of VMs due to DEPLOYCLUSTER_SKIP_VM_MEMORY_CHECK=yes INFO: Detected that all (2) Hub node VMs specified on command line have (1) common shared disk between them (ASM_MIN_DISKS=1) INFO: The (2) VMs passed basic sanity checks and in Running state, sending cluster details as follows: netconfig.ini (Network setup): /SoftOracle/deploycluster/utils/netconfig12cRAC2node.ini params.ini (Overall build options): /SoftOracle/deploycluster/utils/params12c.ini buildcluster: yes INFO: Starting to send configuration details to all (2) VM(s)..... INFO: Sending to VM with a simple name of "rac.0" (Hub node)................. INFO: Sending to VM with a simple name of "rac.1" (Hub node)...... INFO: Configuration details sent to (2) VMs... Check log (default location /u01/racovm/buildcluster.log) on build VM (rac.0)... INFO: deploycluster.py completed successfully at 05:36:49 in 67.7 seconds (0h:01m:07s) Logfile at: /SoftOracle/deploycluster/deploycluster7.log
Y este es el log de la configuración exitosa de las VM:
tail -f /u01/racovm/buildcluster.log ... INFO (node:rac0): Running on: rac0 as oracle: export ORACLE_HOME=/u01/app/oracle/product/12.1.0/dbhome_1; /u01/app/oracle/product/12.1.0/dbhome_1/bin/srvctl status database -d ORCL Instance ORCL1 is running on node rac0 Instance ORCL2 is running on node rac1 INFO (node:rac0): Running on: rac0 as root: /u01/app/12.1.0/grid/bin/crsctl status resource -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Local Resources -------------------------------------------------------------------------------- ora.ASMNET1LSNR_ASM.lsnr ONLINE ONLINE rac0 STABLE ONLINE ONLINE rac1 STABLE ora.DATA.dg ONLINE ONLINE rac0 STABLE ONLINE ONLINE rac1 STABLE ora.LISTENER.lsnr ONLINE ONLINE rac0 STABLE ONLINE ONLINE rac1 STABLE ora.net1.network ONLINE ONLINE rac0 STABLE ONLINE ONLINE rac1 STABLE ora.ons ONLINE ONLINE rac0 STABLE ONLINE ONLINE rac1 STABLE ora.proxy_advm ONLINE ONLINE rac0 STABLE ONLINE ONLINE rac1 STABLE -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE rac0 STABLE ora.asm 1 ONLINE ONLINE rac0 STABLE 2 ONLINE ONLINE rac1 STABLE 3 OFFLINE OFFLINE STABLE ora.cvu 1 OFFLINE OFFLINE STABLE ora.gns 1 ONLINE ONLINE rac0 STABLE ora.gns.vip 1 ONLINE ONLINE rac0 STABLE ora.oc4j 1 OFFLINE OFFLINE STABLE ora.orcl.db 1 ONLINE ONLINE rac0 Open,STABLE 2 ONLINE ONLINE rac1 Open,STABLE ora.rac0.vip 1 ONLINE ONLINE rac0 STABLE ora.rac1.vip 1 ONLINE ONLINE rac1 STABLE ora.scan1.vip 1 ONLINE ONLINE rac0 STABLE -------------------------------------------------------------------------------- INFO (node:rac0): For an explanation on resources in OFFLINE state, see Note:1068835.1 2014-02-16 11:16:07:[clusterstate:Time :rac0] Completed successfully in 164 seconds (0h:02m:44s) 2014-02-16 11:16:13:[buildcluster:Done :rac0] Building 12c RAC Cluster 2014-02-16 11:16:16:[buildcluster:Time :rac0] Completed successfully in 9501 seconds (2h:38m:21s)
Finalmente, para validar que realmente está funcionando me conecto a una de las instancias del RAC:
server:/archivos/oracle # ssh oracle@192.168.56.10 oracle@192.168.56.10's password: [oracle@rac0 ~]$ echo $ORACLE_SID ORCL1 [oracle@rac0 ~]$ sqlplus / as sysdba SQL*Plus: Release 12.1.0.1.0 Production on Sun Feb 16 11:54:26 2014 Copyright (c) 1982, 2013, Oracle. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP, Advanced Analytics and Real Application Testing options SQL> set lines 180 pages 180 SQL> col host_name for a10 SQL> select inst_id, version, instance_name, host_name, status 2 from gv$instance; INST_ID VERSION INSTANCE_NAME HOST_NAME STATUS ---------- ----------------- ---------------- ---------- ------------ 1 12.1.0.1.0 ORCL1 rac0 OPEN 2 12.1.0.1.0 ORCL2 rac1 OPEN
Espero les sea útil.
domingo, 26 de enero de 2014
Oracle SQL Developer 4.0 en OpenSuse y usando PostgreSQL!
Ayer estuve probando la nueva versión del utilitario Oracle SQL Developer que se liberó en diciembre (4.0.0.13), y entre muchas cosas nuevas (ver las 10 razones para usarlo, en inglés), encontré que se puede configurar una conexión a una base PostgreSQL, algo que me interesaba desde hace tiempo.
Si bien PostgreSQL no está dentro de las bases de terceros soportadas, ahora funciona, aunque algunas operaciones dan error (como por ejemplo ver los índices de una tabla), y no tiene las mismas funcionalidades que el utilitario nativo de PostgreSQL psql.
Pero es una buena señal, y con el tiempo se puede convertir en la herramienta necesaria para cualquier DBA que administra varios motores. En mi caso uso habitualmente Oracle, MySQL y PostgreSQL, y ocasionalmente SQL Server, todas administrables desde SQL Developer. Esperemos que en breve se tenga la funcionalidad completa sobre bases PostgreSQL.
Para quienes les interese probarlo, les dejo el detalle de como instalarlo y hacerlo funcionar en OpenSuse 12.3 x64, conectando a una base PostgreSQL 9.2.4 que corre local (instalado del repositorio "openSUSE BuildService - Database").
1) Descargar software
2) Instalar
Dejé los archivos anteriores en el directorio /local/soft/oracle, y desde ahí lo instalé con root:
Si se trata de usar SQL Developer sin instalar la JDK 1.7, da este error:

Esto es porque OpenSuse incluye OpenJDK 1.7, que trae solo JRE (openjdk-1.7.0.6-8.28.3.x86_64):
Así que se debe instalar la JDK 1.7:
Podemos validar donde quedó instalado:
3) Configurar JDK en SQL Developer
Antes de ejecutar SQL Developer se debe modificar su configuración para que use el JDK recién instalado, agregando el path correcto en el archivo de configuración sqldeveloper.conf en la variable SetJavaHome. Lo modifiqué con un editor de texto (vi), dejando comentada la configuración original (../../jdk):
4) Agregar conexión a PostgreSQL
Ahora que está resuelta la instalación, abrimos SQL Developer:
Nos muestra la pantalla de inicio. En mi caso tenía una versión anterior (3.2) por lo que me migró algunas conexiones:

Ahora vamos a la configuración para agregar el driver de PostgreSQL. Esto se hace presionando Tools en el menú superior, y ahí eligiendo Preferences:

Ahora hay que elegir Database, y allí Third Party JDBC Drivers, donde se muestran los drivers ya configurados (en mi caso MySQL y SQL Server):





Si bien PostgreSQL no está dentro de las bases de terceros soportadas, ahora funciona, aunque algunas operaciones dan error (como por ejemplo ver los índices de una tabla), y no tiene las mismas funcionalidades que el utilitario nativo de PostgreSQL psql.
Pero es una buena señal, y con el tiempo se puede convertir en la herramienta necesaria para cualquier DBA que administra varios motores. En mi caso uso habitualmente Oracle, MySQL y PostgreSQL, y ocasionalmente SQL Server, todas administrables desde SQL Developer. Esperemos que en breve se tenga la funcionalidad completa sobre bases PostgreSQL.
Para quienes les interese probarlo, les dejo el detalle de como instalarlo y hacerlo funcionar en OpenSuse 12.3 x64, conectando a una base PostgreSQL 9.2.4 que corre local (instalado del repositorio "openSUSE BuildService - Database").
1) Descargar software
- SQL Developer RPM para linux: sqldeveloper-4.0.0.13.80-1.noarch.rpm
- Java JDK 7: jdk-7u51-linux-x64.rpm
- driver JDBC 4.1 para Postgres 9.3: postgresql-9.3-1100.jdbc41.jar
2) Instalar
Dejé los archivos anteriores en el directorio /local/soft/oracle, y desde ahí lo instalé con root:
oraculo:/local/soft/oracle # rpm -Uvh sqldeveloper-4.0.0.13.80-1.noarch.rpm
Preparing... ################################# [100%]
Updating / installing...
1:sqldeveloper-4.0.0.13.80-1 ################################# [ 50%]
Cleaning up / removing...
2:sqldeveloper-3.2.20.09.87-1 ################################# [100%]
Si se trata de usar SQL Developer sin instalar la JDK 1.7, da este error:
ncalero@oraculo:> sqldeveloper
Oracle SQL Developer
Copyright (c) 1997, 2013, Oracle and/or its affiliates. All rights reserved.
Esto es porque OpenSuse incluye OpenJDK 1.7, que trae solo JRE (openjdk-1.7.0.6-8.28.3.x86_64):
oraculo:~ # rpm -qa | grep -i jdk
java-1_7_0-openjdk-1.7.0.6-8.28.3.x86_64
oraculo:~ # rpm -ql java-1_7_0-openjdk-1.7.0.6-8.28.3.x86_64
/usr/lib64/jvm-exports/java-1.7.0-openjdk
/usr/lib64/jvm-exports/java-1.7.0-openjdk-1.7.0
...
/usr/lib64/jvm/java-1.7.0-openjdk-1.7.0/jre
...
oraculo:~ # /usr/lib64/jvm/java-1.7.0-openjdk-1.7.0/jre/bin/java -version
java version "1.7.0_45"
OpenJDK Runtime Environment (IcedTea 2.4.3) (suse-8.28.3-x86_64)
OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)
Así que se debe instalar la JDK 1.7:
oraculo:/local/soft/oracle # rpm -Uvh jdk-7u51-linux-x64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:jdk-2000:1.7.0_51-fcs ################################# [100%]
Unpacking JAR files...
rt.jar...
jsse.jar...
charsets.jar...
tools.jar...
localedata.jar...
jfxrt.jar...
Podemos validar donde quedó instalado:
oraculo:/local/soft/oracle # rpm -ql jdk-2000:1.7.0_51-fcs
/etc
/etc/.java
/etc/.java/.systemPrefs
...
/usr/java/jdk1.7.0_51/bin
...
oraculo:/local/soft/oracle # /usr/java/jdk1.7.0_51/bin/java -version
java version "1.7.0_51"
Java(TM) SE Runtime Environment (build 1.7.0_51-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.51-b03, mixed mode)
3) Configurar JDK en SQL Developer
Antes de ejecutar SQL Developer se debe modificar su configuración para que use el JDK recién instalado, agregando el path correcto en el archivo de configuración sqldeveloper.conf en la variable SetJavaHome. Lo modifiqué con un editor de texto (vi), dejando comentada la configuración original (../../jdk):
oraculo: # grep SetJavaHome /opt/sqldeveloper/sqldeveloper/bin/sqldeveloper.conf
#SetJavaHome ../../jdk
SetJavaHome /usr/java/jdk1.7.0_51
4) Agregar conexión a PostgreSQL
Ahora que está resuelta la instalación, abrimos SQL Developer:
ncalero@oraculo:~> sqldeveloper
Oracle SQL Developer
Copyright (c) 1997, 2013, Oracle and/or its affiliates. All rights reserved.
Nos muestra la pantalla de inicio. En mi caso tenía una versión anterior (3.2) por lo que me migró algunas conexiones:
Ahora vamos a la configuración para agregar el driver de PostgreSQL. Esto se hace presionando Tools en el menú superior, y ahí eligiendo Preferences:
Ahora hay que elegir Database, y allí Third Party JDBC Drivers, donde se muestran los drivers ya configurados (en mi caso MySQL y SQL Server):
Con el botón "Add Entry ..." se debe elegir el archivo que bajamos antes, ubicado en /local/soft/oracle/postgresql-9.3-1100.jdbc41.jar.
Una vez elegido, presionamos el botón Select en este diálogo, y OK en el anterior para confirmar el cambio.
Para probar su funcionamiento creamos una nueva conexión. En este ejemplo usando el botón con el símbolo de más en el menú "Connections" de la izquierda:
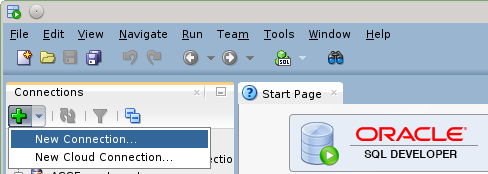
Se abre el diáologo para ingresar los datos de la conexión, donde aparece una nueva pestaña "PostgreSQL":
Para probar su funcionamiento creamos una nueva conexión. En este ejemplo usando el botón con el símbolo de más en el menú "Connections" de la izquierda:
Se abre el diáologo para ingresar los datos de la conexión, donde aparece una nueva pestaña "PostgreSQL":
En este ejemplo me voy a conectar a una base en el mismo equipo donde corre SQL Developer.
Si la base estuviera en otro servidor hay que revisar que se tenga permiso de acceso, tanto a nivel de IP (archivo pg_hba.conf) como en el usuario que se conecta a la base de datos.
Una vez que se ingresan los datos (hostname, port, username, password), se puede validar que la conexión funciona presionando el botón "Choose Database" para que nos muestre las bases a las que podemos conectarnos, y debemos elegir una de ellas para esta conexión:
Si la base estuviera en otro servidor hay que revisar que se tenga permiso de acceso, tanto a nivel de IP (archivo pg_hba.conf) como en el usuario que se conecta a la base de datos.
Una vez que se ingresan los datos (hostname, port, username, password), se puede validar que la conexión funciona presionando el botón "Choose Database" para que nos muestre las bases a las que podemos conectarnos, y debemos elegir una de ellas para esta conexión:
Luego de elegida una base, podemos probar que la conexión funciona con el botón "Test" (aunque al funcionar la carga del combo de bases anteriores ya tenemos la pista de que va a funcionar). El resultado de este test se muestra en la parte inferior izquierda de esta ventana, donde dice Status:, como se ve en la siguiente captura marcado en rojo.

Al presionar Connect abrimos la conexión y podemos navegar en los objetos de la base tal como lo hacemos en Oracle, y ejecutar sentencias SQL.
Espero les sea útil.
Suscribirse a:
Entradas (Atom)